Qwen3-Omni: Revolutionary Native Omni-Modal Foundation Model Redefining AI Multimodal Interaction
Qwen3-Omni is a next-generation native omnimodal large model that seamlessly processes multiple input forms, including text, images, audio, and video, and generates both text and natural speech output through real-time streaming responses.
Qwen3-Omni: Revolutionary Native Omni-Modal Foundation Model Redefining AI Multimodal Interaction
Qwen3-Omni is a next-generation native omni-modal foundation model that seamlessly processes text, images, audio, and video inputs while generating both text and natural speech outputs through real-time streaming responses. We have introduced multiple architectural upgrades to enhance model performance and efficiency, achieving 32 open-source SOTA and 22 overall SOTA results in 36 audio and audio-video benchmark tests, surpassing closed-source models like Gemini-2.5-Pro.
Important Note: While Qwen3-Omni represents the cutting edge of multimodal AI technology, it is not yet available on consumer platforms. However, you can experience similar powerful capabilities right now with SuperMaker AI's free tools - Veo 3 Video Generator and AI Voice Generator - no login required!
What is Qwen3-Omni?
Qwen3-Omni is a native end-to-end multilingual omni-modal foundation model developed by Alibaba's Qwen team. It processes text, images, audio, and video, delivering real-time streaming responses in both text and natural speech formats. The model adopts an innovative Thinker-Talker architecture design, achieving ultra-low latency audio and video interaction experiences.
Qwen3-Omni's Core Advantage: Native omni-modal support with mixed-modal training performance that doesn't degrade compared to pure single-modal training while significantly enhancing cross-modal capabilities.
Core Features of Qwen3-Omni
Native Omni-Modal Support
Qwen3-Omni provides native multimodal support through early text-first pretraining and mixed multimodal training:
- No Performance Degradation: Achieves powerful audio and audio-video results while maintaining unimodal text and image performance
- Enhanced Cross-Modal Capabilities: Significantly improves multimodal understanding and generation abilities
- Unified Architecture Design: Thinker-Talker architecture enables unified processing of text and speech
Outstanding Performance
Qwen3-Omni demonstrates exceptional performance across comprehensive evaluations:
- Audio Task SOTA: Achieves 32 open-source SOTA and 22 overall SOTA in 36 audio/video benchmark tests
- Surpasses Closed-Source Models: Performance exceeds Gemini 2.5 Pro, Seed-ASR, GPT-4o-Transcribe, and other closed-source models
- ASR Performance: Automatic speech recognition, audio understanding, and voice conversation performance comparable to Gemini 2.5 Pro
- Multilingual Support: Supports 119 text languages, 19 speech input languages, and 10 speech output languages
Ultra-Low Latency Interaction
Qwen3-Omni achieves industry-leading real-time interaction performance:
- Audio Dialogue Latency: Pure model end-to-end audio dialogue latency as low as 211ms
- Video Dialogue Latency: Video dialogue latency as low as 507ms
- Real-Time Streaming Generation: Supports first-frame token direct streaming decoding to audio output
- Natural Turn-Taking: Supports natural conversation turn-taking and immediate text or speech responses
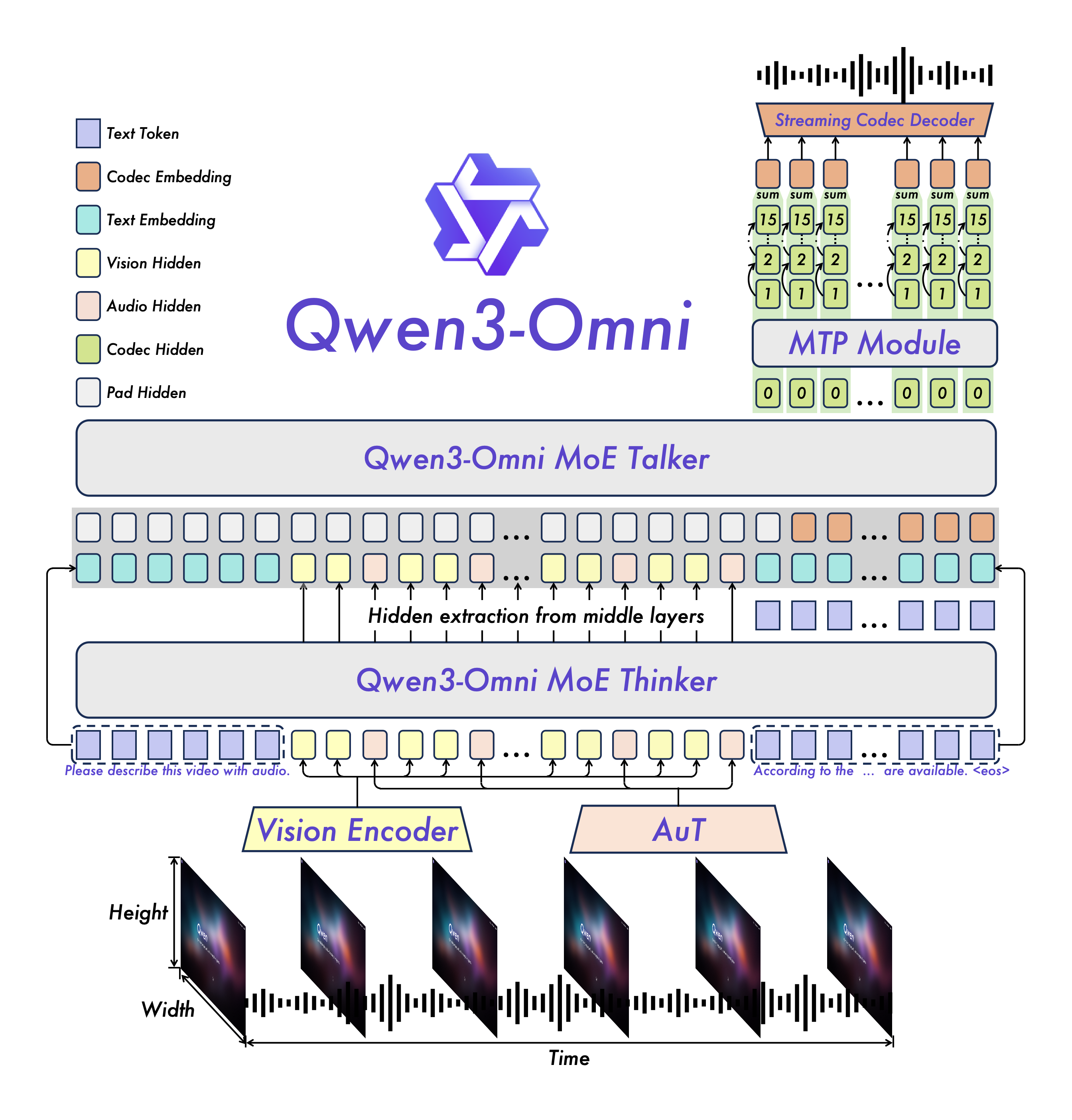
Innovative Architecture of Qwen3-Omni
Thinker-Talker Architecture Design
Qwen3-Omni adopts an innovative Thinker-Talker architecture:
- Thinker Component: Responsible for text generation and chain-of-thought reasoning, supporting audio, video, and text inputs
- Talker Component: Focuses on streaming speech token generation, directly receiving high-level semantic representations from Thinker
- MoE Architecture: Both Thinker and Talker use MoE architecture, supporting high concurrency and fast inference
Multi-Codebook Technology
To achieve ultra-low latency streaming generation, Talker predicts multi-codebook sequences through autoregressive methods:
- Frame-by-Frame Generation: At each decoding step, the MTP module outputs residual codebooks for the current frame
- Code2Wav Synthesis: Subsequently, Code2Wav synthesizes corresponding waveforms, achieving frame-by-frame streaming generation
- Multi-Codebook Autoregressive: Each step generates one codec frame, with MTP module simultaneously outputting remaining residual codebooks
AuT Audio Encoder
Qwen3-Omni uses an AuT model trained on 20 million hours of audio data:
- Universal Audio Representation: Possesses extremely strong general audio representation capabilities
- Multilingual Support: Supports 19 speech input languages and 10 speech output languages
- Long Audio Processing: Supports audio understanding up to 30 minutes in length
Application Scenarios of Qwen3-Omni
Audio Processing and Understanding
Qwen3-Omni demonstrates powerful capabilities in the audio domain:
- Speech Recognition: Supports multilingual and long audio speech recognition
- Speech Translation: Supports speech-to-text and speech-to-speech translation
- Music Analysis: Detailed analysis and appreciation of any music, including style, genre, rhythm, etc.
- Sound Analysis: Description and analysis of various sound effects and audio signals
- Audio Captioning: Generates detailed audio captions for any audio input
Video Understanding and Generation
Qwen3-Omni excels equally in video processing:
- Video Description: Detailed description of video content
- Video Navigation: Generates navigation commands from first-person motion videos
- Scene Transition Analysis: Analysis of scene transitions in videos
- Audio-Visual Q&A: Answers arbitrary questions in audio-visual scenarios, demonstrating the model's ability to model temporal alignment between audio and video
Multimodal Interaction
Qwen3-Omni supports rich multimodal interaction scenarios:
- Audio-Visual Dialogue: Conversational interaction with the model using audio-visual inputs
- Tool Calling: Supports function calls for efficient integration with external tools/services
- Personalized Customization: Supports system prompt customization to modify response styles and personas
Experience Similar Capabilities on SuperMaker AI Platform
Free Access to Advanced AI Tools
While Qwen3-Omni represents the cutting edge of multimodal AI technology, you can experience similar powerful capabilities right now on SuperMaker AI platform - completely free and no login required.
Veo 3 Video Generator - Free Video Creation
Experience professional-grade video generation with the Veo 3 Video Generator:
- Text-to-Video: Create stunning videos using natural language descriptions
- Image-to-Video: Transform static images into dynamic, engaging videos
- Character Consistency: Maintain character appearance throughout your video content
- Audio Integration: Generate synchronized dialogue, sound effects, and background music
- Professional Quality: Hollywood-quality results with integrated audio generation
AI Voice Generator - Free Voice Creation
Create natural, professional voice content with the SuperMaker AI Voice Generator:
- Multiple Voice Options: Choose from various natural-sounding voices
- High-Quality Synthesis: Generate clear, fluent speech output
- Easy-to-Use Interface: Simple text-to-speech conversion
- Commercial Ready: Use generated voices for professional projects
Three Model Versions of Qwen3-Omni
Qwen3-Omni-30B-A3B-Instruct
Instruction Model, containing both Thinker and Talker:
- Input Support: Audio, video, and text inputs
- Output Capabilities: Audio and text outputs
- Use Cases: General conversation and interaction tasks
Qwen3-Omni-30B-A3B-Thinking
Thinking Model, containing thinking components:
- Chain-of-Thought Reasoning: Possesses chain-of-thought reasoning capabilities
- Input Support: Audio, video, and text inputs
- Output Limitation: Text output only (no audio output)
- Use Cases: Complex reasoning and analysis tasks
Qwen3-Omni-30B-A3B-Captioner
Audio Captioning Model, fine-tuned from the Instruct model:
- Professional Capabilities: Generates detailed, low-hallucination descriptions for any audio input
- Contains Thinking Components: Supports audio input and text output
- Fills Community Gap: First general-purpose audio captioning model in the open-source community

Technical Advantages of Qwen3-Omni
No Performance Degradation Across Modalities
Qwen3-Omni achieves no performance degradation across modalities through innovative training strategies:
- Early Mixed Training: Mixes single-modal and cross-modal data during early text pretraining
- Performance Maintenance: Mixed-modal training performance doesn't degrade compared to pure single-modal training
- Capability Enhancement: Simultaneously significantly enhances cross-modal capabilities
Real-Time Streaming Processing
Qwen3-Omni achieves true real-time interaction:
- End-to-End Streaming: AuT, Thinker, Talker + Code2wav full pipeline streaming
- First-Frame Decoding: Supports first-frame token direct streaming decoding to audio output
- Natural Turn-Taking: Supports natural conversation turn-taking and immediate responses
Tool Calling Capabilities
Qwen3-Omni supports powerful tool calling functionality:
- Function Call: Supports function calls for efficient integration with external tools/services
- Audio Function Calling: Uses audio input to execute function calls, enabling agent-like behaviors
- Flexible Integration: Can easily integrate various external services and APIs

Real-World Application Cases
Education Sector
Qwen3-Omni demonstrates enormous potential in the education field:
- Intelligent Teaching Assistant: Provides personalized teaching through voice and video understanding
- Multilingual Learning: Supports text interaction in 119 languages and speech understanding in 19 languages
- Real-Time Q&A: Low-latency real-time question answering and explanations
Content Creation
Qwen3-Omni provides powerful support for content creators:
- Multimodal Content Generation: Combines text, images, audio, and video to generate rich content
- Real-Time Collaboration: Supports real-time multimodal interaction and collaboration
- Personalized Customization: Customizes creative styles through system prompts
Enterprise Applications
Qwen3-Omni plays an important role in enterprise scenarios:
- Intelligent Customer Service: Multimodal intelligent customer service systems
- Meeting Transcription: Real-time audio transcription and summarization
- Data Analysis: Multimodal data analysis and insights
User Reviews and Feedback
"Revolutionary Multimodal Experience!"
"Qwen3-Omni's multimodal capabilities amazed me! It not only understands my voice commands but also processes video and images simultaneously with extremely fast response times. This completely transformed my workflow!"
- Zhang Engineer, AI Product Manager
"Perfect Multilingual Support!"
"As a multilingual content creator, Qwen3-Omni's support for 119 text languages and 19 speech input languages allows me to easily handle content in different languages, improving efficiency by 10x!"
- Li Teacher, Multilingual Education Expert
"Ultra-Low Latency Real-Time Interaction!"
"Qwen3-Omni's 211ms audio dialogue latency gave me a true real-time AI interaction experience. Whether it's speech recognition or multimodal understanding, it reaches professional-grade standards!"
- Wang Designer, Creative Director
Conclusion: Experience the Future of Multimodal AI Today
Qwen3-Omni represents the future of multimodal AI interaction: native omni-modal, ultra-low latency, multilingual support. While this cutting-edge technology is still being integrated into consumer platforms, you can experience similar powerful capabilities right now.
Try Advanced AI Tools for Free
Don't wait for the future - start creating professional content today with SuperMaker AI's free tools:
- Veo 3 Video Generator - Create Hollywood-quality videos with integrated audio
- SuperMaker AI Voice Generator - Generate natural, professional voice content
No login required, completely free to use!
Note: While Qwen3-Omni showcases the future of multimodal AI, SuperMaker AI currently offers powerful video and voice generation tools that provide similar creative capabilities for immediate use.
Ready to experience advanced AI content creation? Try SuperMaker AI's free tools now and start your creative journey today!
This article introduces Qwen3-Omni's revolutionary multimodal capabilities while highlighting currently available alternatives on SuperMaker AI platform for immediate creative use.


