The Exciting Release of Qwen3-TTS: A New Era in Open-Source Text-to-Speech
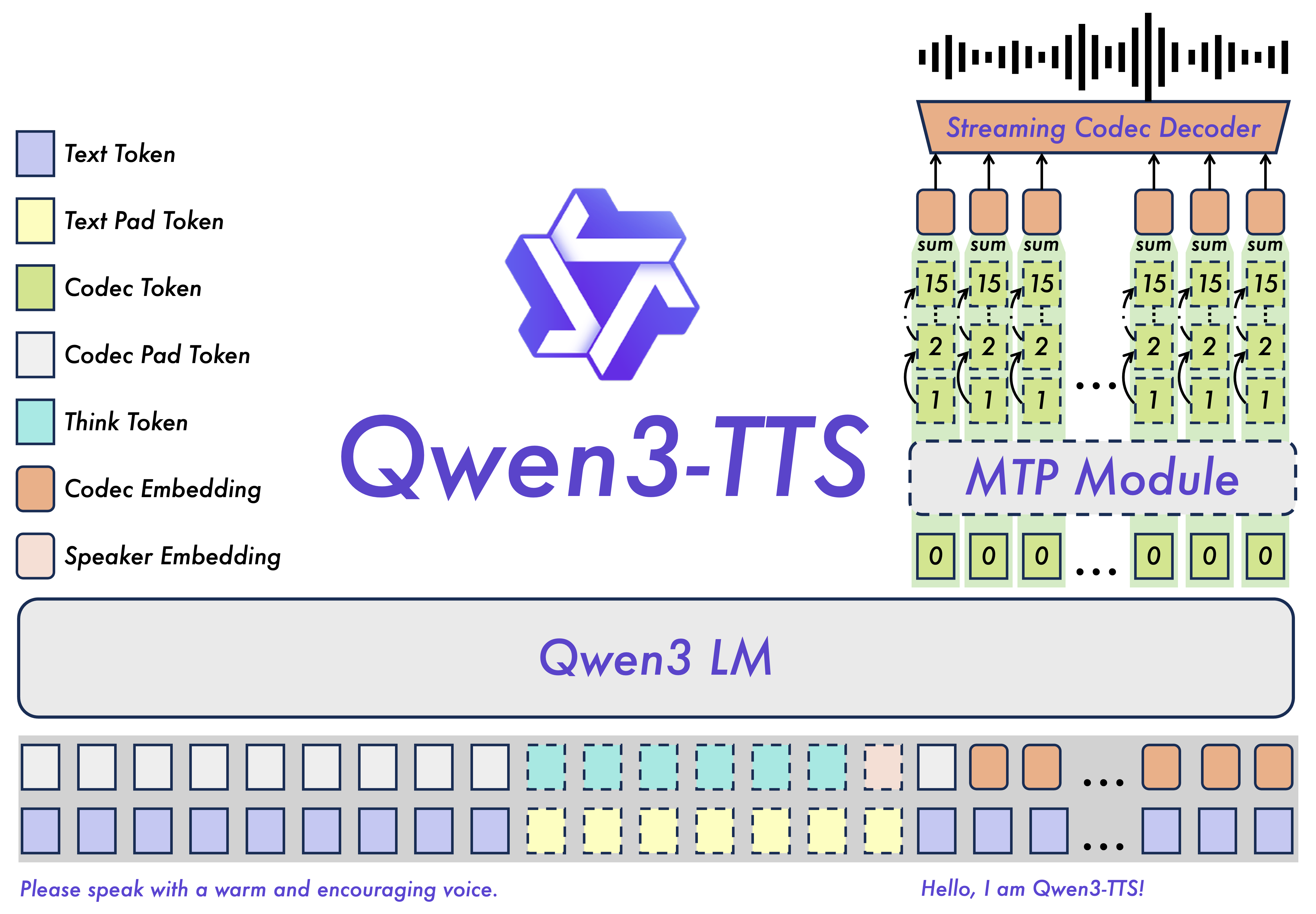
Qwen3-TTS brings together advanced capabilities in voice cloning, voice design, high-quality speech generation, and real-time streaming synthesis, making it one of the most versatile and accessible TTS solutions available today.
Introduction
In the rapidly advancing world of artificial intelligence, the open-sourcing of Qwen3-TTS stands out as a major breakthrough in text-to-speech (TTS) technology. Developed by Alibaba Cloud's Qwen team, this powerful model family was fully released to the public in January 2026, building on initial announcements and developments from late 2025. Qwen3-TTS brings together advanced capabilities in voice cloning, voice design, high-quality speech generation, and real-time streaming synthesis, making it one of the most versatile and accessible TTS solutions available today.
This release reflects the growing importance of natural, controllable, and multilingual speech AI in applications like virtual assistants, content creation, education, accessibility tools, and interactive media. By open-sourcing the entire series under the Apache 2.0 license, the Qwen team has empowered developers, researchers, and creators worldwide to build innovative voice experiences. In this blog post, we'll explore the key aspects of Qwen3-TTS, its standout features, performance highlights, and why this launch matters so much for the AI community.
For a practical way to experience the model hands-on, including demos of voice cloning and design, check out Qwen3-TTS on SuperMaker AI.

Background and Release Timeline
The Qwen series has established itself as a leader in open-source AI, starting with powerful language models and expanding into multimodal domains including vision and audio. Qwen3-TTS represents the dedicated evolution of their speech generation efforts, leveraging generative techniques such as flow-matching to achieve smoother and more expressive outputs than traditional TTS approaches.
Initial teasers and partial capabilities appeared in late 2025, with the full family—including multiple variants and tokenizers—officially open-sourced on January 21, 2026. The announcement highlighted the model's training on over 5 million hours of diverse speech data, enabling robust multilingual performance and fine-grained control. This timing aligns perfectly with surging demand for high-fidelity, low-latency voice AI in real-world products.
The open release includes not only the core models but also supporting components like tokenizers, inference code, and detailed documentation, lowering barriers for adoption and experimentation.

Core Features That Define Qwen3-TTS
Qwen3-TTS goes far beyond basic text-to-speech conversion. It introduces several groundbreaking features that address long-standing limitations in the field:
Zero-Shot Voice Cloning
With just a short 3-second audio clip from a target speaker, Qwen3-TTS can replicate their voice with impressive fidelity. This capability requires no extensive fine-tuning data, making it ideal for personalized applications such as custom narrations, celebrity-style voiceovers, or preserving unique voices in storytelling projects.
Natural Language Voice Design
One of the most creative aspects is the ability to generate entirely new voices from descriptive text prompts. Describe characteristics like "a warm elderly woman with a slight British accent" or "a energetic young narrator with upbeat enthusiasm," and the model synthesizes a fitting timbre. This feature empowers creators in gaming, animation, and media production to craft bespoke characters without recording sessions.
Expressive and Contextual Speech Synthesis
The model produces remarkably human-like speech, capturing nuances in tone, rhythm, pacing, and emotion based on both the input text and optional natural language instructions. It excels at long-form content, maintaining consistency and expressiveness throughout extended passages—perfect for audiobooks, podcasts, or educational narrations.
Real-Time Streaming with Ultra-Low Latency
Thanks to a dual-track language model architecture and a specialized 12Hz tokenizer, Qwen3-TTS achieves first-token latencies as low as 97ms. This enables seamless streaming synthesis suitable for live applications like conversational agents, real-time translation dubbing, or interactive voice experiences.
Robust Instruction Following
Qwen3-TTS demonstrates strong robustness to noisy or imperfect input text and follows detailed prompts to adjust output characteristics. Whether specifying excitement, calmness, emphasis on certain words, or stylistic flourishes, the model responds accurately, reducing the need for manual editing.
Additional variants like Qwen3-TTS-Flash introduce dozens of high-quality preset timbres covering a wide range of genders, ages, regional accents, and character styles, providing quick options for deployment.
Check It Out Qwen3-TTS on SuperMaker AI.
Multilingual and Dialect Capabilities
Qwen3-TTS supports 10 major languages natively:
- Chinese
- English
- Japanese
- Korean
- German
- French
- Russian
- Portuguese
- Spanish
- Italian
It further incorporates various dialects and accents, enhancing naturalness for global users. In multilingual benchmarks, including challenging test sets, the model has demonstrated state-of-the-art stability and low word error rates, making it reliable across diverse linguistic contexts.
Model Variants and Technical Architecture
The Qwen3-TTS family offers flexibility through different parameter scales and specialized variants:
- Base models (Qwen3-TTS-12Hz-1.7B-Base and Qwen3-TTS-12Hz-0.6B-Base): General-purpose for cloning and standard TTS tasks, with the 1.7B version providing superior quality and control.
- CustomVoice variants: Include preset speakers for faster integration.
- VoiceDesign variant: Optimized for free-form voice creation from descriptions.
Architecturally, it features a Transformer-based encoder-decoder design optimized for efficient, low-latency inference. Two tokenizers support different use cases: a 25Hz version for semantic richness and integration with other Qwen audio models, and the 12Hz version for ultra-low bitrate and streaming performance. Model files remain reasonably sized (around 2.5GB to 4.5GB), allowing deployment on a variety of hardware from edge devices to servers.
Performance Highlights
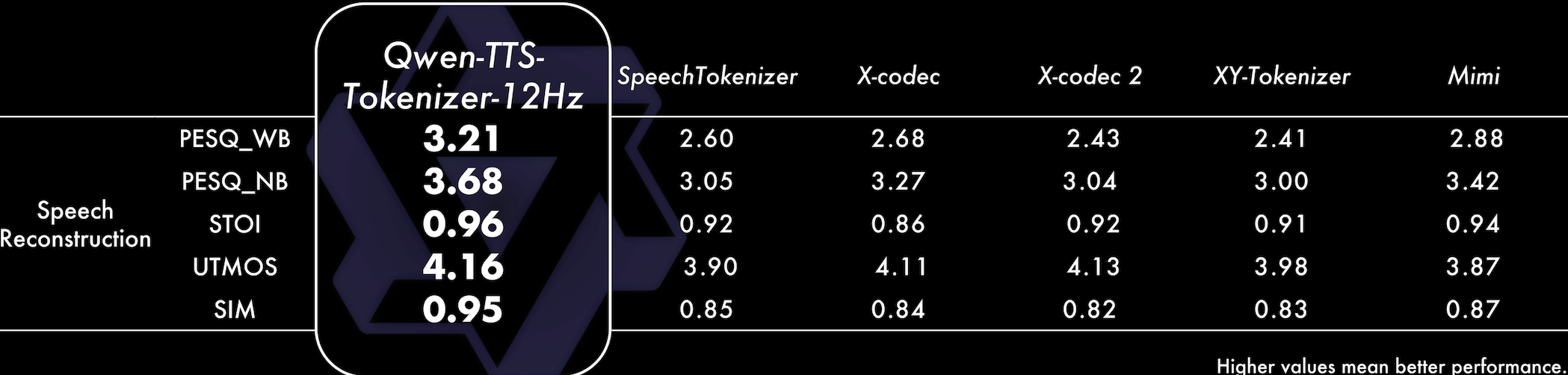
Extensive evaluations place Qwen3-TTS at the forefront of current TTS technology. It achieves top results on benchmarks for stability, expressiveness, and multilingual accuracy, often outperforming closed-source alternatives in objective metrics like word error rate and subjective listening tests for naturalness. Long-form synthesis tests further confirm its ability to sustain quality over minutes-long outputs without degradation.
These strong results, combined with its open nature, position Qwen3-TTS as a valuable resource for both research advancements and practical deployments.
Availability and How to Get Started
The complete Qwen3-TTS series is fully open-sourced, with models, tokenizers, and code available through official channels. Developers can download everything needed to run inferences locally or integrate into projects. The Qwen API also provides cloud access with generous free tiers for quick prototyping.
Communities are already sharing examples, fine-tuning guides, and creative demos, fostering rapid adoption and iteration.
If you're ready to try voice cloning, design new voices, or generate expressive speech without complex setup, Qwen3-TTS on SuperMaker AI offers an accessible interface to explore these capabilities directly.
Why This Release Matters
The launch of Qwen3-TTS democratizes advanced TTS technology, enabling more inclusive and creative audio experiences worldwide. From improving accessibility for visually impaired users to enhancing educational content in multiple languages, or powering next-generation interactive applications, the potential is enormous.
As AI continues to blend modalities, models like Qwen3-TTS pave the way for richer, more human-centered interactions. The open-source approach ensures that innovation isn't limited to a few organizations but can flourish across the global community.
Final Thoughts
The January 2026 release of Qwen3-TTS is more than just another model drop—it's a leap forward in making high-quality, controllable, and multilingual speech synthesis widely available. With its blend of technical excellence, creative features, and commitment to openness, Qwen3-TTS is set to influence countless projects in the months and years ahead.
Whether you're a developer, researcher, content creator, or simply curious about the future of voice AI, this is an exciting moment to engage with the technology. Dive in, experiment, and see where your ideas take you.


