Create Natural Speech with Qwen3-TTS Audio Model
Open source multilingual text to speech with voice cloning and voice design for creators, developers, and teams who need natural, controllable, and reliable speech across products, media, and interactive experiences.
Qwen3-TTS is a state of the art TTS family from the Qwen team built for real world voice production. On SuperMaker, you get a clean web workflow that removes deployment friction and lets you focus on creative direction, voice style, and output quality. From short ads to long podcasts, Qwen3-TTS delivers consistent speaker identity, stable tone, and expressive rhythm that feels human and polished.

More AI Voice Generation Tools
Explore our collection of specialized AI voice generators designed for different creative needs and styles



Generate Expressive Speech with Qwen3-TTS
Turn text into natural speech with Qwen3-TTS for controllable tone, rhythm, and multilingual consistency across narration, assistants, and content pipelines.
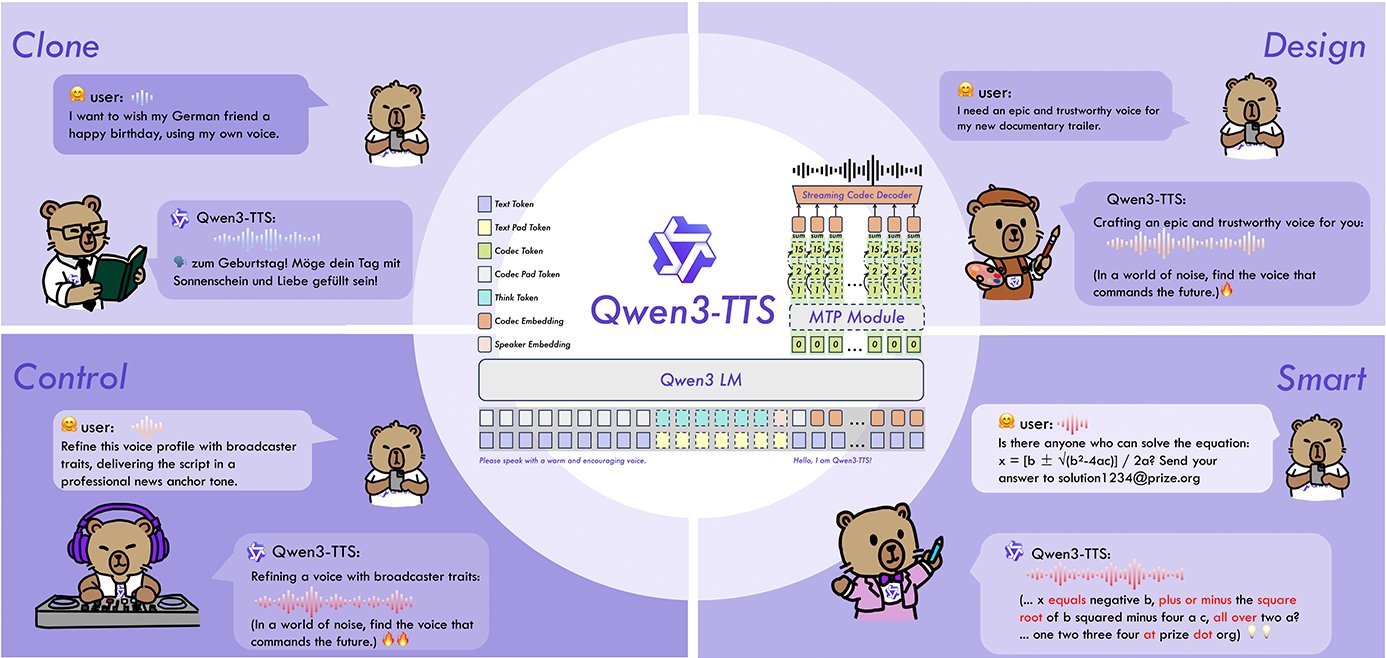
Qwen3-TTS brings high fidelity speech synthesis to creators and developers with a focus on control and stability. Built on a dual track architecture and a 12Hz tokenizer, Qwen3-TTS delivers fast streaming, stable prosody, and robust performance on long form speech. The Qwen3-TTS family includes 0.6B and 1.7B parameter options for different quality and compute needs, plus specialized Qwen3-TTS variants for VoiceDesign and CustomVoice. Use Qwen3-TTS to build consistent narrators, multilingual voiceovers, or interactive assistants that respond quickly and sound natural. Qwen3-TTS is equally effective for quick prototypes and production pipelines, enabling teams to shorten turnaround from script to final audio. SuperMaker provides the Qwen3-TTS entry with a simple UI so teams can experiment, iterate, and publish without managing infrastructure, while keeping control over speaker identity, pacing, and emotional tone.
How to Use Qwen3-TTS
Create high quality speech in four simple steps on SuperMaker, from script to final audio with Qwen3-TTS cloning, Qwen3-TTS design, and Qwen3-TTS streaming controls in one place.

Write Your Script
Enter the text you want to speak, including punctuation and pacing cues. Qwen3-TTS follows semantics and style cues for natural delivery, so Qwen3-TTS narration can feel calm, energetic, or conversational. For longer projects, Qwen3-TTS keeps voice identity consistent from start to finish.

Choose a Voice
Select a preset speaker, clone a voice from a short clip, or design a new voice with a description. Qwen3-TTS lets you define age, timbre, emotion, or delivery style to match your brand or character. With Qwen3-TTS you can maintain a branded narrator or craft unique personas for storytelling.

Generate and Preview
Stream audio in real time and tune tone, rhythm, and emotion. Qwen3-TTS delivers the first audio packet in milliseconds, making Qwen3-TTS suitable for demos, chatbots, or live previews. Adjust and re generate quickly without waiting for batch processing.

Export Audio
Download your speech and use it in videos, podcasts, education, games, or assistants. Qwen3-TTS audio stays consistent across long segments, so Qwen3-TTS projects remain coherent. Reuse the Qwen3-TTS voice for future updates to keep the brand sound intact.
Features of Qwen3-TTS
Explore the capabilities that make Qwen3-TTS a leading open source TTS model family, balancing control, speed, and quality for production use. Each feature is built to reduce iteration time while keeping voices consistent and expressive.

Multilingual Mastery
- Supports 10 mainstream languages including English, Chinese, Japanese, Korean, German, French, Spanish, Portuguese, Russian, and Italian.
- Maintains speaker consistency across languages and code switching, so a single narrator can stay recognizable in global campaigns.
- Ideal for localization, multilingual courses, international marketing, and cross region product demos where uniform voice identity matters.

3 Second Voice Cloning
- Clone a speaker from a short reference clip in roughly three seconds.
- High similarity and stable timbre with minimal input, even for longer scripts and multiple takes.
- Great for narration, character voices, podcasts, trailers, and branded assistants that need a consistent voice across seasons or campaigns.

Voice Design from Descriptions
- Create a new voice from text like age, emotion, accent, and style.
- The Voice Design variant interprets nuanced prompts and turns creative direction into unique timbre.
- Rapidly prototype characters without studio recording, then iterate on style in minutes while keeping your narrative consistent.
Real Time Streaming
- 12Hz tokenizer enables low bitrate and low latency output for streaming experiences.
- First audio packet in about 97 ms for interactive apps and live previews.
- Reliable long form synthesis with consistent prosody, pacing, and clear articulation, even for multi paragraph scripts.
Who Uses Qwen3-TTS
Qwen3-TTS fits creators, teams, and developers who need reliable multilingual speech synthesis with flexible voice control, from prototyping to production.
Content Creators
Qwen3-TTS generates narration for videos, podcasts, and shorts with consistent tone and fast iteration. Use Qwen3-TTS to swap scripts without re recording and keep the same voice across episodes, ads, or serialized content.
Education and Training
Qwen3-TTS builds multilingual lessons and language learning content with native sounding voices, and Qwen3-TTS keeps the same speaker identity when you switch languages for global classrooms.
Accessibility
Qwen3-TTS powers screen readers and assistive tools with natural, expressive speech that users can understand for long periods without fatigue. Qwen3-TTS pacing and prosody improve accessibility.

Product and UX
Qwen3-TTS prototypes voice experiences for assistants, apps, and interactive demos in minutes with low latency streaming and responsive playback. Use Qwen3-TTS for rapid testing of dialogs, tone, and UX behavior.
Gaming and Entertainment
Qwen3-TTS designs character voices or clones a narrator with precise style control for games, trailers, and immersive storytelling. Qwen3-TTS maintains continuity across DLC, seasonal updates, or episodic releases.

Enterprise Operations
Qwen3-TTS creates branded voice experiences for customer service and marketing at scale, including multilingual IVR, product explainers, and onboarding. Qwen3-TTS ensures every touchpoint sounds like the same brand voice.
User Feedback
Teams use Qwen3-TTS on SuperMaker for fast, controllable speech generation and dependable results across content types.
VoiceDesign lets us prototype character voices without any recording sessions. Qwen3-TTS lets us iterate on age, accent, and emotion in a few clicks, then send drafts to writers and directors for feedback. Qwen3-TTS shortens our pre production pipeline and helps us align character personality with the script before we commit to full recordings. Qwen3-TTS gives us a reliable baseline voice that we can refine into the final performance.
Streaming latency is low enough for live demos and interactive assistants. Qwen3-TTS delivers the first audio packet quickly so conversations feel responsive, and Qwen3-TTS voice quality stays stable as the dialog grows. We used Qwen3-TTS to prototype a customer support bot and it felt natural in real time, which helped us validate product direction before building a full stack integration.
The multilingual quality is impressive and keeps the same speaker identity. Qwen3-TTS saves a lot of effort when localizing content because we no longer have to cast separate voices for each region. Our training videos now sound like they come from the same narrator in every language, and Qwen3-TTS improves brand consistency and reduces coordination across teams.
We needed a reliable way to generate voiceovers for product tutorials in multiple languages. Qwen3-TTS delivered clean pronunciation and stable pacing across long scripts. The Qwen3-TTS streaming preview made it easy to review sections quickly, and the final Qwen3-TTS exports were ready to drop into our video editor without extra cleanup.




Frequently Asked Questions
Answers to common questions about the Qwen3-TTS audio model, its capabilities, and how to use Qwen3-TTS on SuperMaker for production ready speech.
Qwen3-TTS is an open source family of text to speech models from the Qwen team. Qwen3-TTS uses a dual track language model and a 12Hz speech tokenizer to generate natural, expressive speech with low latency streaming. The Qwen3-TTS architecture separates semantic planning from acoustic generation, which improves stability and makes long form synthesis more consistent.
Yes. Qwen3-TTS supports 10 languages and keeps speaker identity consistent when switching languages or using code switching. Qwen3-TTS is useful for global teams that need a single narrator across regional versions, and Qwen3-TTS reduces localization cost because you do not need a separate voice actor per language.
With a short reference clip, Qwen3-TTS can clone a speaker in about 3 seconds. Qwen3-TTS preserves timbre and style for longer scripts, making Qwen3-TTS suitable for narration, branded voices, and character continuity.
Use the VoiceDesign variant to describe a voice in text, such as age, emotion, accent, and style. Qwen3-TTS generates a new voice that matches your description, letting you prototype characters quickly without recording.
Qwen3-TTS is released under the Apache 2.0 license with 0.6B and 1.7B model sizes. SuperMaker provides a simple entry to test Qwen3-TTS online, so you can explore Qwen3-TTS cloning, Qwen3-TTS design, and multilingual output without local setup.
Start Using Qwen3-TTS on SuperMaker
Qwen3-TTS is a state of the art TTS family from the Qwen team built for real world voice production. Qwen3-TTS supports 10 languages, 3 second voice cloning, and description based voice design with ultra low latency streaming. The Qwen3-TTS models use a dual track language model plus a 12Hz speech tokenizer, which reduces bitrate while keeping natural prosody and clear articulation. This makes Qwen3-TTS suitable for long form narration, responsive assistants, and multilingual content at scale. On SuperMaker, you get a clean web workflow that removes deployment friction and lets you focus on creative direction, voice style, and output quality. From short ads to long podcasts, Qwen3-TTS delivers consistent speaker identity, stable tone, and expressive rhythm that feels human and polished, even when you iterate quickly across multiple versions.
